Как создать абзац, если все пробелы сначала - удаляются автоматический?
Пример (сначала было два пробела)
Как в phpbbex создать абзац?
Список разделов › phpBBex 1.x (поддерживается) › Поддержка 1.x
Сообщений: 24
• Страница 1 из 2 • 1, , 2
![]() dream.reckless » 02.04.2013, 09:34
dream.reckless » 02.04.2013, 09:34
- dream.reckless
- Автор темы

- Репутация: 5
- С нами: 13 лет 4 месяца
![]() dream.reckless » 02.04.2013, 10:07
dream.reckless » 02.04.2013, 10:07
Только так? Другого варианта нет?
- dream.reckless
- Автор темы
- Репутация: 5
- С нами: 13 лет 4 месяца
![]() Борис Бердичевский » 02.04.2013, 10:38
Борис Бердичевский » 02.04.2013, 10:38
Есть у меня BB код -- dd
- Код: Выделить всё
- Борис Бердичевский


- Репутация: 11
- С нами: 13 лет
![]() dream.reckless » 02.04.2013, 10:39
dream.reckless » 02.04.2013, 10:39
Ребята, "костыли" то это не совсем то что хотелось бы..
Добавлено спустя 20 секунд:
Это все - я как бы знаю просто.....)
Добавлено спустя 20 секунд:
Это все - я как бы знаю просто.....)
- dream.reckless
- Автор темы
- Репутация: 5
- С нами: 13 лет 4 месяца
![]() Борис Бердичевский » 02.04.2013, 10:40
Борис Бердичевский » 02.04.2013, 10:40
А это код джастификации (выравнивания справа-слева)
- Код: Выделить всё
[just]{TEXT}[/just]
- Код: Выделить всё
<div align="justify">{TEXT}</div>
- Борис Бердичевский
- Репутация: 11
- С нами: 13 лет
![]() Борис Бердичевский » 02.04.2013, 10:43
Борис Бердичевский » 02.04.2013, 10:43
А хотелось бы и рыбку съесть и т.д....dream.reckless:не совсем то что хотелось бы..

- Борис Бердичевский
- Репутация: 11
- С нами: 13 лет
![]() factotum » 02.04.2013, 10:53
factotum » 02.04.2013, 10:53
\includes\functions_content.php.
найти:
найти:
- Код: Выделить всё
function bbcode_nl2br($text)
{
// custom BBCodes might contain carriage returns so they
// are not converted into <br /> so now revert that
$text = str_replace(array("\n", "\r"), array('<br />', "\n"), $text);
return $text;
}
- Код: Выделить всё
function bbcode_nl2br($text)
{
$text = trim($text);
$text = preg_replace('~(\r\n|\n){2,}|$~', "\001", $text);
$text = nl2br($text);
$text = preg_replace('/(.*?)\001/s', '<p>$1</p>' . "\n", $text);
return $text;
}
- factotum
- Откуда: Люксембург
- Репутация: 234
- С нами: 14 лет
![]() VEG » 02.04.2013, 11:25
VEG » 02.04.2013, 11:25
dream.reckless, лишние пробелы в начале строки и между словами игнорируются — это нормальное поведение. В сети не принято выделять абзац «красной строкой». Абзацы выделяют промежутками между ними.
Вообще в каком-нибудь Word делать красную строку пробелами тоже плохо — там для этого есть стили. Впрочем, как и в HTML :)
Вообще в каком-нибудь Word делать красную строку пробелами тоже плохо — там для этого есть стили. Впрочем, как и в HTML :)
- VEG
- Администратор

- Откуда: Finland
- Репутация: 1698
- С нами: 14 лет
![]() factotum » 02.04.2013, 11:28
factotum » 02.04.2013, 11:28
В идеале должно быть как то так:
- Код: Выделить всё
function replace_wrap_with_p($text) {
$pre_tags = array();
if ( trim($text) === '' )
return '';
$text = $text . "\n"; // just to make things a little easier, pad the end
$text = preg_replace('|<br />\s*<br />|', "\n\n", $text);
// Space things out a little
$allblocks = '(?:table|thead|tfoot|caption|col|colgroup|tbody|tr|td|th|div|dl|dd|dt|ul|ol|li|pre|select|option|form|map|area|blockquote|address|math|style|p|h[1-6]|hr|fieldset|noscript|samp|legend|section|article|aside|hgroup|header|footer|nav|figure|figcaption|details|menu|summary)';
$text = preg_replace('!(<' . $allblocks . '[^>]*>)!', "\n$1", $text);
$text = preg_replace('!(</' . $allblocks . '>)!', "$1\n\n", $text);
$text = str_replace(array("\r\n", "\r"), "\n", $text); // cross-platform newlines
$text = preg_replace("/\n\n+/", "\n\n", $text); // take care of duplicates
// make paragraphs, including one at the end
$texts = preg_split('/\n\s*\n/', $text, -1, PREG_SPLIT_NO_EMPTY);
$text = '';
foreach ( $texts as $tinkle )
$text .= '<p>' . trim($tinkle, "\n") . "</p>\n";
$text = preg_replace('|<p>\s*</p>|', '', $text); // under certain strange conditions it could create a P of entirely whitespace
$text = preg_replace('!<p>([^<]+)</(div|address|form)>!', "<p>$1</p></$2>", $text);
$text = preg_replace('!<p>\s*(</?' . $allblocks . '[^>]*>)\s*</p>!', "$1", $text); // don't pee all over a tag
$text = preg_replace("|<p>(<li.+?)</p>|", "$1", $text); // problem with nested lists
$text = preg_replace('|<p><blockquote([^>]*)>|i', "<blockquote$1><p>", $text);
$text = str_replace('</blockquote></p>', '</p></blockquote>', $text);
$text = preg_replace('!<p>\s*(</?' . $allblocks . '[^>]*>)!', "$1", $text);
$text = preg_replace('!(</?' . $allblocks . '[^>]*>)\s*</p>!', "$1", $text);
$text = preg_replace('|(?<!<br />)\s*\n|', "<br />\n", $text); // optionally make line breaks
$text = preg_replace('!(</?' . $allblocks . '[^>]*>)\s*<br />!', "$1", $text);
$text = preg_replace('!<br />(\s*</?(?:p|li|div|dl|dd|dt|th|pre|td|ul|ol)[^>]*>)!', '$1', $text);
$text = preg_replace( "|\n</p>$|", '</p>', $text );
return $text;
}
- factotum
- Откуда: Люксембург
- Репутация: 234
- С нами: 14 лет
![]() dream.reckless » 02.04.2013, 11:32
dream.reckless » 02.04.2013, 11:32
VEG, способ что был предложен - можно использовать, как Вы считаете? 
- dream.reckless
- Автор темы
- Репутация: 5
- С нами: 13 лет 4 месяца
![]() VEG » 02.04.2013, 12:05
VEG » 02.04.2013, 12:05
Второй вариант кода от factotum будет медленным — слишком много регулярок, и совсем не ясно, зачем так много логики в таком простом деле :)
Вообще
Сразу скажу, что не тестировал — написал код прямо здесь. Также кто-то может посчитать недостатком то, что этот код генерирует совместимый в HTML5 код (используется автоматическое закрытие <p> и <br>), а для XHTML он не годится (для его должен подойти первый вариант). В стандартном стиле phpBBex используется HTML5.
Пока писал пришло понимание того, что первая строка всё равно останется без абзаца. По идее можно заменить
Но поскольку bbcode_nl2br используется всюду, это может что-нибудь поломать. Всё равно скорее всего эффект вам не понравится и вы от его откажетесь, ибо красные строки в вебе выглядят архаичными :)
Не забудьте в CSS дописать стиль для выделения всех абзацев красной строкой:
Добавлено спустя 9 минут 19 секунд:
Вообще
bbcode_nl2br используется десятки раз на каждой странице, поэтому она должна быть быстрой. Первый выглядит рабочим вариантом, но я бы написал ещё проще, с одной регуляркой:- Код: Выделить всё
function bbcode_nl2br($text)
{
$text = trim($text);
$text = str_replace(array("\r\n", "\r"), "\n", $text);
$text = preg_replace('#(\n){2,}#', '<p>', $text);
$text = str_replace("\n", '<br>', $text);
return $text;
}
Сразу скажу, что не тестировал — написал код прямо здесь. Также кто-то может посчитать недостатком то, что этот код генерирует совместимый в HTML5 код (используется автоматическое закрытие <p> и <br>), а для XHTML он не годится (для его должен подойти первый вариант). В стандартном стиле phpBBex используется HTML5.
Пока писал пришло понимание того, что первая строка всё равно останется без абзаца. По идее можно заменить
return $text; на return '<p>' . $text; в коде для принудительного добавления абзаца для первой строки. Получится так:- Код: Выделить всё
function bbcode_nl2br($text)
{
$text = trim($text);
$text = str_replace(array("\r\n", "\r"), "\n", $text);
$text = preg_replace('#(\n){2,}#', '<p>', $text);
$text = str_replace("\n", '<br>', $text);
return '<p>' . $text;
}
Но поскольку bbcode_nl2br используется всюду, это может что-нибудь поломать. Всё равно скорее всего эффект вам не понравится и вы от его откажетесь, ибо красные строки в вебе выглядят архаичными :)
Не забудьте в CSS дописать стиль для выделения всех абзацев красной строкой:
- Код: Выделить всё
p
{
text-indent: 35px;
}
Добавлено спустя 9 минут 19 секунд:
Если быть точным, то без авторских комментариев нужно время, чтобы разобраться в логике этого кода. А поскольку кода много и выглядит он навёрнутым, я просто не стал разбираться в нём. Если factotum объяснит подробнее, зачем так много логики — тогда, возможно, станет понятна необходимость в подобном коде.VEG:и совсем не ясно, зачем так много логики в таком простом деле
- VEG
- Администратор
- Откуда: Finland
- Репутация: 1698
- С нами: 14 лет
![]() factotum » 02.04.2013, 12:19
factotum » 02.04.2013, 12:19
VEG,
$text = "пишу в одну строку
пишу с новой строки
пишу с нового абзаца"
return = "<p>пишу в одну строку<br>
пишу с новой строки</p>
<p>пишу с нового абзаца</p>"
$text = "пишу в одну строку, добавляя теги <$allblocks></$allblocks>"
return "<p>пишу в одну строку, добавляя теги</p><$allblocks></$allblocks>"
$text = "пишу в одну строку, добавляя теги с новой
<$allblocks></$allblocks>"
return "<p>пишу в одну строку, добавляя теги с новой</p>
<$allblocks></$allblocks>"
$text = "пишу в одну строку
пишу с новой строки
пишу с нового абзаца"
return = "<p>пишу в одну строку<br>
пишу с новой строки</p>
<p>пишу с нового абзаца</p>"
$text = "пишу в одну строку, добавляя теги <$allblocks></$allblocks>"
return "<p>пишу в одну строку, добавляя теги</p><$allblocks></$allblocks>"
$text = "пишу в одну строку, добавляя теги с новой
<$allblocks></$allblocks>"
return "<p>пишу в одну строку, добавляя теги с новой</p>
<$allblocks></$allblocks>"
Последний раз редактировалось factotum 02.04.2013, 12:26, всего редактировалось 1 раз.
- factotum
- Откуда: Люксембург
- Репутация: 234
- С нами: 14 лет
![]() VEG » 02.04.2013, 12:23
VEG » 02.04.2013, 12:23
factotum, да, но в HTML5 тег <p> автоматически закрывается перед всеми блочными тегами. Этим свойством тега <p> можно пользоваться — это не является нарушением стандарта. От XHTML в phpBBex сознательно отказались как раз по причине того, что HTML5 более гибок в плане корректности и простоты кода. К слову, в phpBB 3.1 тоже HTML5 по умолчанию :)
- VEG
- Администратор
- Откуда: Finland
- Репутация: 1698
- С нами: 14 лет
![]() factotum » 02.04.2013, 12:31
factotum » 02.04.2013, 12:31
VEG,
черновик на все случаи :)
убрать не нужное проще, чем добавить.
как минимум хочется сохранить и <br>
один перенос = <br>
два подряд = <p>
остальное нужно смотреть. не факт, что незакрытые теги не аукнутся в каком то случае.
Добавлено спустя 2 минуты 27 секунд:
еще хватает браузеров без поддержки html5.
темпы прогресса phpBB 3.1 говорят о том, что запросто можно дождаться и html6
черновик на все случаи :)
убрать не нужное проще, чем добавить.
как минимум хочется сохранить и <br>
один перенос = <br>
два подряд = <p>
остальное нужно смотреть. не факт, что незакрытые теги не аукнутся в каком то случае.
Добавлено спустя 2 минуты 27 секунд:
еще хватает браузеров без поддержки html5.
темпы прогресса phpBB 3.1 говорят о том, что запросто можно дождаться и html6
- factotum
- Откуда: Люксембург
- Репутация: 234
- С нами: 14 лет
![]() VEG » 02.04.2013, 12:48
VEG » 02.04.2013, 12:48
Верно, так и задумывалось. Два подряд и более — это <p>, иначе — обычный <br>.factotum:как минимум хочется сохранить и <br>
один перенос = <br>
два подряд = <p>
Не уверен, что подобное поведение тега <p> было заложено стандартном HTML4, но древние браузера вроде IE5-6 корректно закрывают все <p>. Многие вещи, которые не входили в HTML4, но браузера уже умели их делать, вошли в HTML5.factotum:еще хватает браузеров без поддержки html5.
- VEG
- Администратор
- Откуда: Finland
- Репутация: 1698
- С нами: 14 лет
![]() factotum » 02.04.2013, 13:01
factotum » 02.04.2013, 13:01
не доверяю я им.VEG:браузера вроде IE5-6
немного не оттуда но:
в CSS ...\9; стучалось только в IE9. Вчера внезапно выяснилось, что хак проглатывает и IE10. вместо помощи от хака получились шикарные костыли.
Добавлено спустя 12 минут 34 секунды:
и да. боты как минимум гугля не желают переходить на html5. из-за чего можно встретить белиберду в результатах поиска, описании для Г+/ФБ/...
- factotum
- Откуда: Люксембург
- Репутация: 234
- С нами: 14 лет
![]() VEG » 02.04.2013, 13:30
VEG » 02.04.2013, 13:30
factotum, автозакрытие <p> — это фишка тега, а не костыль или хак. Как и отсутствие необходимости закрывать <br> с <img>.
Изначально в HTML существовали такие теги с подобным поведением. Потом ребята из W3C решили усложнить всем жизнь, и начали продвигать XHTML, который был строгим подмножеством XML со всеми его недостатками. Только веб-разработчики забыли, что XHTML не предназначен для написания руками — это исключительно машинный формат. Руками его очень легко сломать. Например, при наличии незакрытого <br> в любом месте страницы пользователь не увидит ничего, кроме:
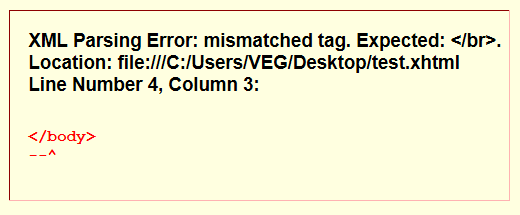
И как показывает практика, процентов 90 из всех страниц с доктайпом XHTML падают показанным выше способом при разборе XHTML парсером. Ситуацию спасает то, поклонникам XHTML мало рассказывали о том, что браузер не смотрит на DOCTYPE при выборе парсера, он смотрит на MIME-тип документа в заголовке content-type. И так сложилось, что в целях совместимости вместо
Потом создатели браузеров объединились против буквоедов из W3C и организовали WHATWG, в недрах которого они и стали развивать HTML5, а W3C уже был вынужден присоединиться к этому празднику жизни.
К чему я это всё? Браузера достаточно умны, чтобы разобраться в таких простых вещах, как «когда нужно закрыть тег <p>» или «тег <br> сразу же закрывает сам себя». По спецификации тег <p> будет закрыт автоматически перед любым блочным элементом и перед закрытием родительского тега. Эта логика реализуется проще, чем декодирование и отображение картинки в формате JPEG, например.
Добавлено спустя 4 минуты 48 секунд:
Изначально в HTML существовали такие теги с подобным поведением. Потом ребята из W3C решили усложнить всем жизнь, и начали продвигать XHTML, который был строгим подмножеством XML со всеми его недостатками. Только веб-разработчики забыли, что XHTML не предназначен для написания руками — это исключительно машинный формат. Руками его очень легко сломать. Например, при наличии незакрытого <br> в любом месте страницы пользователь не увидит ничего, кроме:
И как показывает практика, процентов 90 из всех страниц с доктайпом XHTML падают показанным выше способом при разборе XHTML парсером. Ситуацию спасает то, поклонникам XHTML мало рассказывали о том, что браузер не смотрит на DOCTYPE при выборе парсера, он смотрит на MIME-тип документа в заголовке content-type. И так сложилось, что в целях совместимости вместо
application/xhtml+xml практически все CMS (включая и phpBB 3) отдают text/html. В результате документ вроде как и XHTML (по DOCTYPE), но браузер парсит его как HTML, поэтому ничего и не падает.Потом создатели браузеров объединились против буквоедов из W3C и организовали WHATWG, в недрах которого они и стали развивать HTML5, а W3C уже был вынужден присоединиться к этому празднику жизни.
К чему я это всё? Браузера достаточно умны, чтобы разобраться в таких простых вещах, как «когда нужно закрыть тег <p>» или «тег <br> сразу же закрывает сам себя». По спецификации тег <p> будет закрыт автоматически перед любым блочным элементом и перед закрытием родительского тега. Эта логика реализуется проще, чем декодирование и отображение картинки в формате JPEG, например.
Добавлено спустя 4 минуты 48 секунд:
Вы действительно думаете, что компания, которая делает один из лучших браузеров, не в состоянии научить своего робота разбирать HTML5? :)factotum:и да. боты как минимум гугля не желают переходить на html5. из-за чего можно встретить белиберду в результатах поиска, описании для Г+/ФБ/...
- VEG
- Администратор
- Откуда: Finland
- Репутация: 1698
- С нами: 14 лет
Сообщений: 24
• Страница 1 из 2 • 1, , 2